

Electric Next is a new approach that we've adopted to building ElectricSQL. It's informed by the lessons learned building the previous system and inspired by new insight from Kyle Mathews joining the team.
What started as tinkering is now the way forward for Electric. So, what's changed and what does it mean for you?
What is Electric Next?
Electric Next was a clean rebuild of the Electric sync engine that now forms the basis of ElectricSQL moving forwards.
We created a new repo and started by porting the absolute minimum code necessary from the previous repo. Once we were confident that Electric Next was the way forward, we froze the old system and moved the new code into our main repo at https://github.com/electric-sql/electric.
The new approach provides an HTTP API for syncing Shapes of data from Postgres. This can be used directly or via client libraries and integrations. It's also simple to write your own client in any language.
Why build a new system?
Electric has its heritage in distributed database research. When we started, our plan was to use this research to build a next-generation distributed database. Cockroach for the AP side of the CAP theorem. However, the adoption dynamics for creating a new database from scratch are tough. So we pivoted to building a replication layer for existing databases.
This allowed us to do active-active replication between multiple Postgres instances, in the cloud or at the edge. However, rather than stopping at the edge, we kept seeing that it was more optimal to take the database-grade replication guarantees all the way into the client.
So we built a system to sync data into embedded databases in the client. Where our core technology could solve the concurrency challenges with local-first software architecture. Thus, ElectricSQL was born, as an open source platform for building local-first software.
Optimality and complexity
To go from core database replication technology to a viable solution for building local-first software, we had to build a lot of stuff. Tooling for migrations, permissions, client generation, type-safe data access, live queries, reactivity, drivers, etc.
Coming from a research background, we wanted the system to be optimal. As a result, we often picked the more complex solution from the design space and, as a vertically integrated system, that solution became the only one available to use with Electric.
For example, we designed the DDLX rule system in a certain way, because we wanted authorization that supported finality of local writes. However, rules (and our rules) are only one way to do authorization in a local-first system. Many applications would be happy with a simpler solution, such as Postgres RLS or a server authoritative middleware.
These decisions not only made Electric more complex to use but also more complex to develop. Despite our best efforts, this has slowed us down and tested the patience of even the most forgiving of our early adopters.
Many of those early adopters have also reported performance and reliability issues.
The complexity of the stack has provided a wide surface for bugs. So where we've wanted to be focusing on core features, performance and stability, we've ended up fixing issues with things like docker networking, migration tooling and client-side build tools.
The danger, articulated by Teej in the tweet below, is building a system that demos well, with magic sync APIs but that never actually scales out reliably. Because the very features and choices that make the demo magic, prevent the system from being simple enough to be bulletproof in production.
Refocusing our product strategy
One of the many insights that Kyle has brought is that successful systems evolve from simple systems that work. This is Gall's law:
“A complex system that works is invariably found to have evolved from a simple system that worked.”
This has been echoed in conversations we've had with Paul Copplestone at Supabase. His approach to successfully building our type of software is to make the system incremental and composable, as reflected in the Supabase Architecture guide:
Supabase is composable. Even though every product works in isolation, each product on the platform needs to 10x the other products.
To make a system that's incremental and composable, we need to decouple the Electric stack. So it's not a one-size-fits-all vertical stack but, instead, more of a loosely coupled set of primitives around a smaller core. Where we do the essential bits and then allow our users to choose how to integrate and compose these with other layers of the stack.
This aligns with the principle of Worse is Better, defined by Richard P. Gabriel:
Software quality does not necessarily increase with functionality: there is a point where less functionality ("worse") is a preferable option ("better") in terms of practicality and usability.
Gabriel contrasts "Worse is Better" with a make the "Right Thing" approach that aims to create the optimal solution. Which sounds painfully like our ambitions to make an optimal local-first platform. Whereas moving functionality out of scope, will actually allow us to make the core better and deliver on the opportunity.
The motivation for Electric Next
So, hopefully now our motivation is clear. We needed to find a way to simplify Electric and make it more loosely coupled. To pare it back to it's core and iterate on solid foundations.
What's changed?
Electric Next is a sync engine, not a local-first software platform.
It can be used for a wide range of use cases, syncing data into apps, workers, services, agents and environments. These include but are not limited to local-first software development.
Sync engine
When we look at our stack, the part that we see as most core is the sync engine.
This is the component of Electric that syncs data between Postgres and local clients. Consuming Postgres logical replication, managing partial replication using Shapes and syncing data to and from clients over a replication protocol. It’s where there’s the most complexity. Where we can add the most value and is hardest to develop yourself.
Core responsibilities
We now see Electric as a sync engine that does partial replication on top of Postgres. We've pushed other, non-core, aspects of the system out of scope, as we pare down to our essential core and then iterate on this to re-build the capabilities of the previous system.
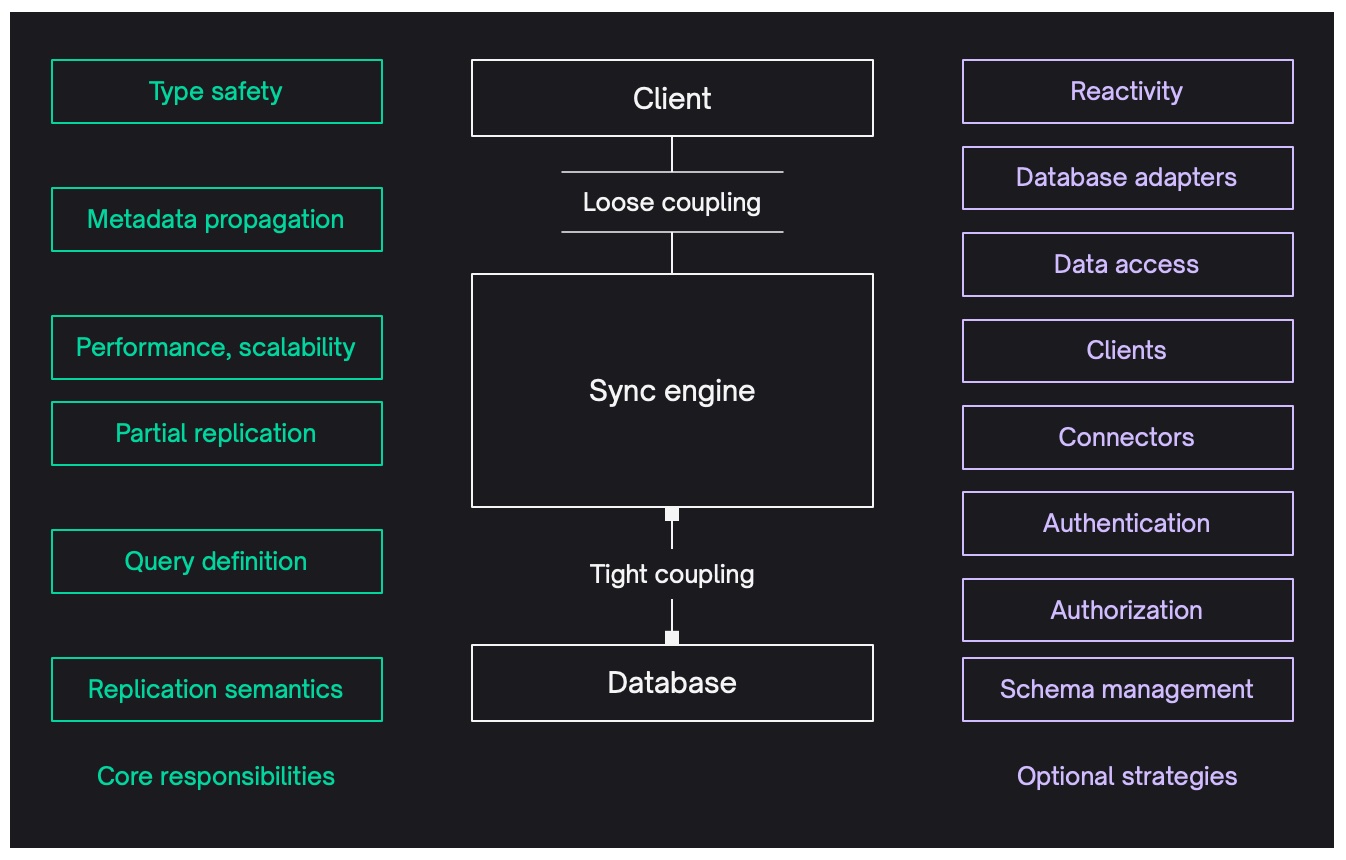
The diagramme above and table below summarise what we see as core and what we've pushed out of scope.
| Aspect | Is it core? | Who should/can provide? |
|---|---|---|
| Syncing data | yes | Electric |
| Partial replication (Shapes) | yes | Electric |
| Schema management / propagation / matching | partial | Application specific. In some cases it may be useful or necessary to replicate and validate schema information. In others, it can be the responsibility of the client to connect with the correct schema. |
| Type safety in the client | partial | Important in many cases for DX and can be assisted by the sync service (e.g.: by providing an endpoint to query types for a shape). But use of types is optional and in many cases types can be provided by ORMs and other client-libraries. |
| Permissions / authorization | no | There are many valid patterns here. Auth middleware, proxies, rule systems. Authorize at connect, per shape, per row/operation. A sync engine may provide some hooks and options but should not prescribe a solution. |
| Client-side data access library | no | There are many ways of mapping a replication stream to objects, graphs or databases in the client. For example using existing ORMs like Drizzle and Prisma, or reactivity frameworks like LiveStore and TinyBase. |
| Client-side reactivity | no | Client specific. Can be provided by reactivity frameworks. |
| Connection management | no | Client specific. |
| Database adapters | no | Client specific. Can be provided by ORMs and reactivity frameworks. |
| Framework integrations | no | Client specific. Can be provided by reactivity frameworks. |
| Client-side debug tooling | no | Client specific. |
HTTP Protocol
One of the key aspects that has changed in the core sync engine is a switch from the Satellite web socket replication prototol to an HTTP replication protocol.
Switching to an HTTP protocol may at first seem like a regression or a strange fit. Web sockets are build on top of HTTP specifically to serve the kind of realtime data stream that Electric provides. However, they are also more stateful and harder to cache.
By switching to the new HTTP API, the new system:
- minimises state, making the sync engine more reliable and easier to scale out
- integrates with standard HTTP tooling, including proxies and CDNs
This allows us to optimise initial data sync by making sync requests cacheable. And it facilitates moving concerns like authentication and authorization out of scope, as these can be handled by HTTP proxies.
Write patterns
Electric has always been envisaged as an active-active replication system that supports bi-directional sync between clients and the server. This means it syncs data out to clients (the "read path") and syncs data back from clients (the "write path").
The previous Electric supported a single primary write-path pattern — writing through the local database:
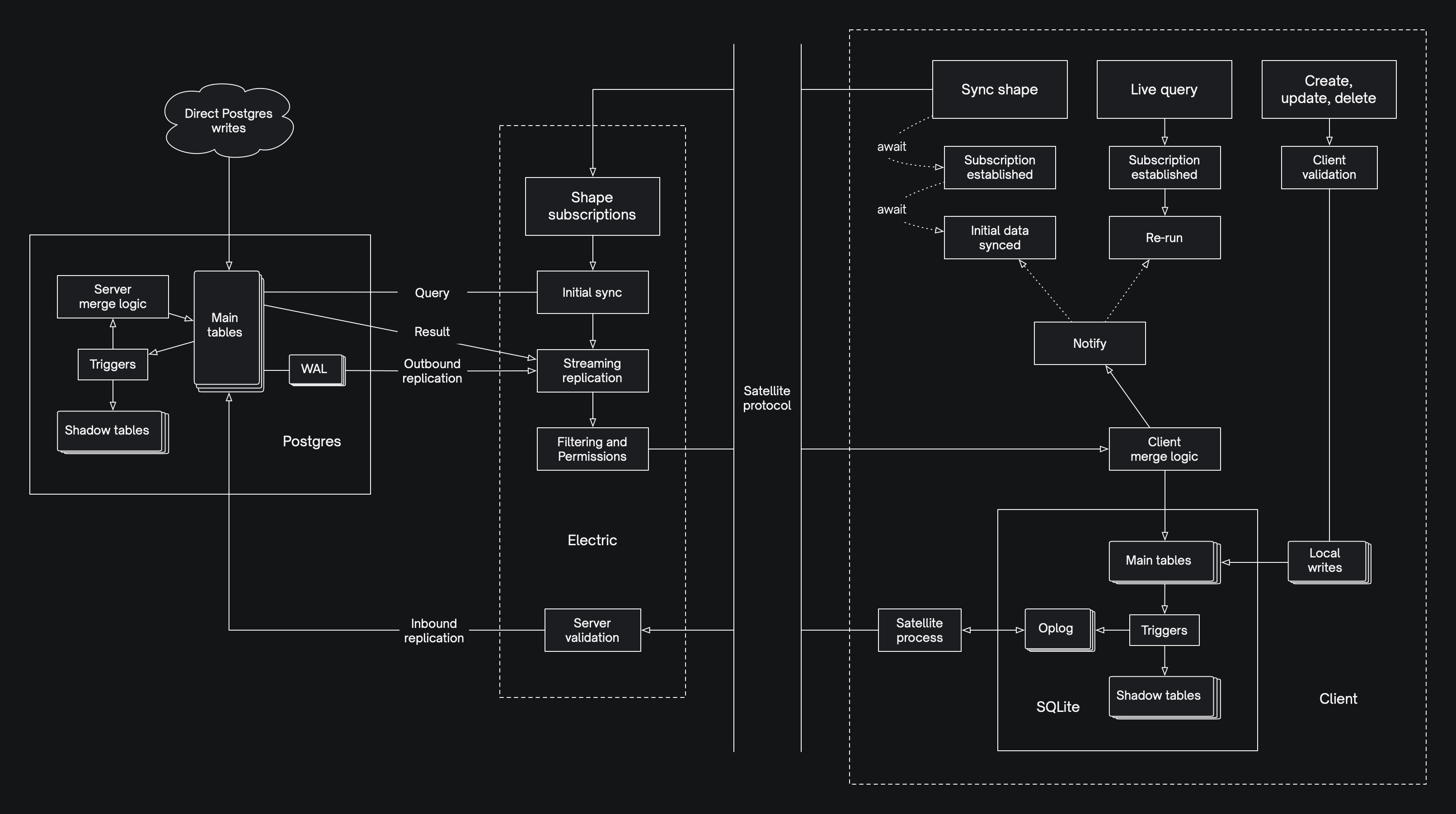
This is very powerful (and abstracts state transfer out of the application domain). However, it is only one of many valid write patterns.
Many applications don't write data at all; for example, syncing data into an application for visualisation or analysis. Some fire-and-forget writes to an ingest API. Other applications write data via API calls, or mutation queues. Some of these are online writes. Some use local optimistic state.
For example, when applying a mutation with Relay you can define an optimisticResponse to update the client store with temporary optimistic state whilst the write is sent to the server. Or to give another example, when making secure transactions a local-first app will explicitly want to send writes to the server, in order to validate and apply them in a secure and strongly consistent environment.
So, following the strategy of paring down to the core and then progressively layering on more complex functionality, Electric Next has taken the following approach:
- start with read-path only
- then add support for optimistic write patterns with tentativity
- then add support for through-the-DB writes
This explicitly reduces the capability of the system in the short term, in order to build a better, more resilient system in the long term. The beauty is that, because we no longer prescribe a write-path strategy, you can choose and if necessary implement any write-path strategy you like.
We will only focus on the more complex strategies ourselves once the simpler ones are bulletproof. And we hope that others, like LiveStore and Drizzle, for example, will build better client-side libraries that we can.
A note on finality of local writes
One of the key differentiators of the previous ElectricSQL system was the ability to write to the local database without conflicts or rollbacks. The principle is finality of local-writes, which means that writes are final, not tentative. I.e.: once a write is accepted locally, it won't be rejected as invalid later on.
In contrast, Electric Next embraces tentativity. With the new system, you can choose your write pattern(s) and the guarantees you want them to provide.
We still believe that a local-first stack that provides finality of local writes can provide a better DX and UX than one that doesn't. Because of the absence of rollbacks. So we are committed in the longer term to building support for finality of local writes. However, it is no longer a key tenet of the system design.
Use cases
The core use case for Electric is to sync subsets of data out of Postgres into local environments, wherever you need the data.
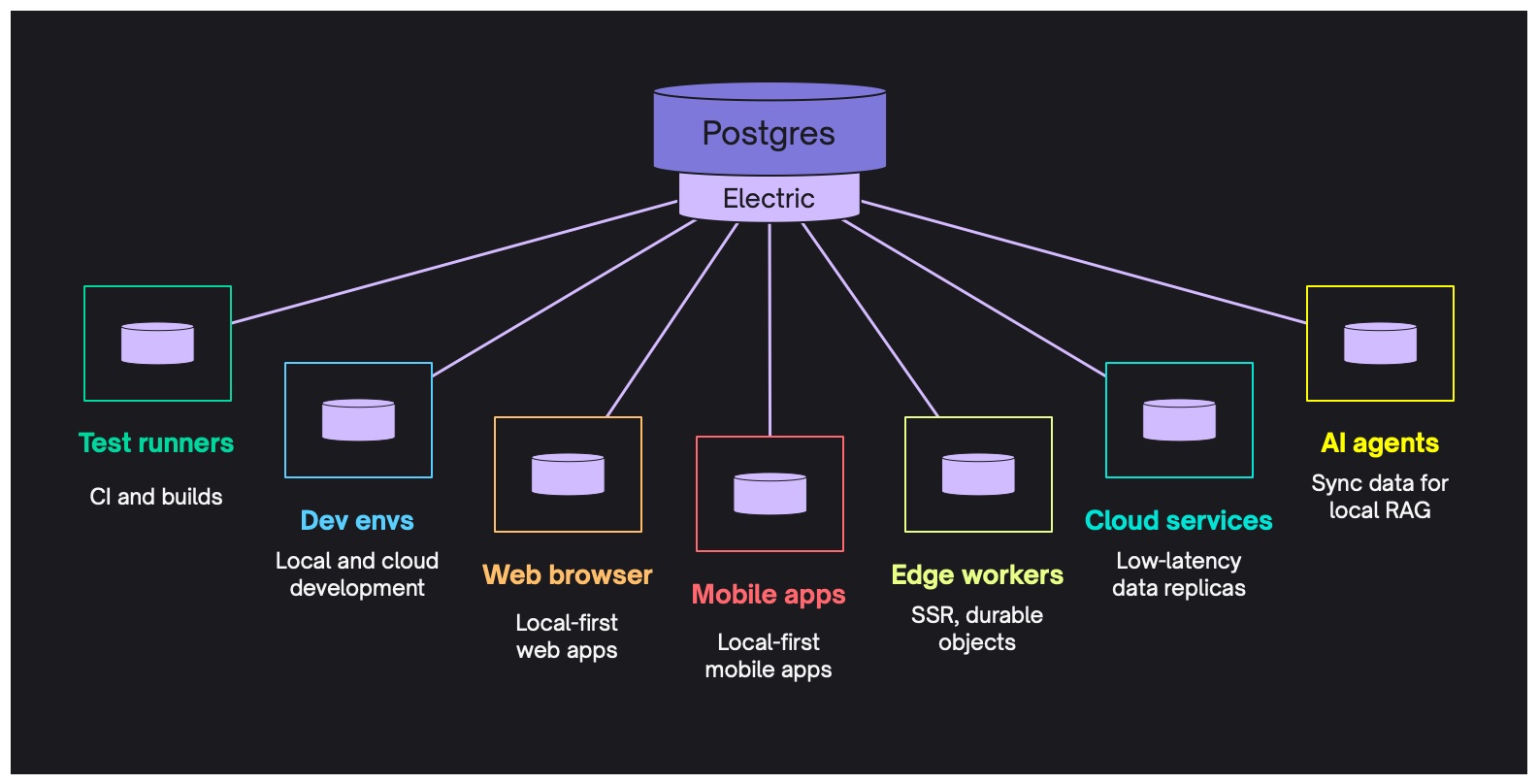
You can sync data into:
- apps, replacing data fetching with data sync
- development environments, for example syncing data into an embedded PGlite
- edge workers and services, for example maintaining a low-latency edge data cache
- local AI systems running RAG, as per the example below
What's the status?
Previous system
Electric Next has superceded the previous Electric.
- some parts of the old system were cherry-picked and ported over
- some parts may be cut out into optional libraries, for example the DDLX implementation
- most parts were not and will not be needed
You're welcome to continue to use the old system and choose your moment to migrate. The code is preserved at electric-sql/electric-old and the website and docs remain published at legacy.electric-sql.com.
However caveat emptor — we are not supporting the old system.
New system
At the time of writing this document, we are early in the development of Electric Next. The repo was created on the 1st July 2024. As a clean re-write, there are many things not-yet supported.
However, even just with the first release of Electric Next you can already sync partial subsets of data from a Postgres database into a wide variety of clients and environments, for example:
- syncing data into local apps using the TypeScript and Elixir clients
- replacing hot-path data fetching and database queries in apps using React, MobX and TanStack
- maintain live caches with automatic invalidation, as per our Redis example
Roadmap
You can track development on Discord and via the GitHub Issues milestones.
Next steps
Electric Next is available to use today. We welcome community contributions.
Using Electric Next
See the:
If you have any questions or need support, ask on the #help-and-support channel in the Electric Discord.
Get involved in development
Electric is open source (Apache 2.0) and developed on GitHub at electric-sql/electric. See the open issues on the repo and the contributing guide.